Los Escribas de IA de Primera Generación Están Mintiendo a Sus Médicos.
Diagnósticos alucinados. Hallazgos fabricados. Las palabras de los pacientes retorcidas en jerga médica que nunca dijeron. La industria lo llama "tasas de error aceptables." Nosotros lo llamamos inaceptable.
Última actualización: Febrero 2026
Un estudio de 2025 de Mount Sinai encontró que cuando los modelos de lenguaje grandes encuentran entrada clínica errónea, no señalan el error— lo elaboran en hasta el 83% de los casos.
Esto no es un error. Es una inevitabilidad arquitectónica de los sistemas de IA de un solo prompt que intentan hacer todo a la vez—escuchar, entender, extraer, interpretar y generar—todo en una pasada.
¿Qué Dice la Investigación Sobre la Seguridad de los Escribas de IA?
No descubrimos estos problemas a través de investigación de marketing. Los encontramos en literatura clínica revisada por pares—los mismos estudios que deberían haber detenido el lanzamiento de la industria.
Investigación Revisada por ParesLa Cifra del 1-3% es Engañosa
Los proveedores citan "tasas de alucinación del 1-3%" de estudios controlados. Pero eso es bajo condiciones ideales—audio limpio, un solo hablante, casos sencillos. Los servicios de urgencias reales tienen hablantes superpuestos, ruido de fondo, pacientes que se contradicen e intérpretes.
El estudio de Mount Sinai probó qué pasa cuando la IA encuentra el tipo de entrada imperfecta que es inevitable en la práctica clínica. El resultado: las tasas de alucinación subieron al 50-83% dependiendo del modelo.
¿Cuáles Son los 5 Modos de Falla de los Escribas de IA de Primera Generación?
La investigación clínica ha identificado patrones de falla sistemáticos en la IA ambiental de primera generación. Estos no son casos extremos—son inevitabilidades arquitectónicas de sistemas de una sola pasada.
Los sistemas de IA fabrican contenido clínico que nunca se discutió. Un estudio de 2024 encontró que GPT-4o produjo información incorrecta o demasiado generalizada en el 42% de los resúmenes de notas médicas.
"Me mareé subiendo las escaleras"
"Episodio sincopal. Se recomienda estudio cardíaco y signos vitales ortostáticos."
Cuando los pacientes dicen 'oleadas,' la IA escribe 'cólico.' Cuando dicen 'sudando,' la IA escribe 'diaforesis.' Esto no es traducción—es interpretación. La terminología médica implica juicio clínico para el cual la IA no está calificada.
"El dolor viene y va en oleadas"
"Dolor abdominal cólico intermitente"
La investigación muestra que el 66-87% de las notas clínicas contienen frases de cobertura que expresan incertidumbre. Los sistemas de IA eliminan sistemáticamente esta incertidumbre, presentando hechos seguros donde los pacientes dieron posibilidades vacilantes.
"Podría ser alérgico a la penicilina—mi mamá me dijo que tuve una reacción de bebé"
(nada—alergia eliminada completamente)
Los pacientes reales se contradicen. 'Sin dolor de pecho.' Luego después: 'Quizás una pequeña opresión.' La IA de primera generación elige una respuesta—usualmente la primera—ocultando la ambigüedad diagnóstica que sus médicos necesitan ver.
"No, no realmente... bueno, quizás un poco de presión"
"Niega dolor de pecho"
Cuando la extracción falla, no puedes depurarlo. Las arquitecturas de un solo prompt no ofrecen rastro de auditoría, ni verificación etapa por etapa. Las métricas estándar de NLP 'correlacionan mal con la relevancia clínica, la corrección factual o la seguridad del paciente.'
"(Encuentro de trauma complejo con múltiples hablantes)"
(Fuente desconocida de errores, sin trazabilidad)
¿Quién Es Responsable Cuando la Documentación de IA Falla?
La mayoría de los escribas de IA operan sin supervisión de la FDA, clasificados como "herramientas administrativas" en lugar de dispositivos médicos. Esto crea una brecha regulatoria donde los proveedores no enfrentan responsabilidad por errores de documentación.
"La doctrina legal de respondeat superior hace al proveedor de salud responsable de la exactitud del expediente médico, independientemente de si fue generado por un humano o un escriba de IA."
— Texas Medical Liability Trust, Consideraciones de Gestión de Riesgos
Los errores de documentación no solo afectan la atención al paciente—debilitan la defensibilidad legal. Según los aseguradores de mala praxis, "algunos casos con buena medicina se resuelven debido a mala documentación" y "los jurados pueden creer que la documentación plagada de errores indica falta de atención al detalle."
Escala de Adopción
7,000+ médicos
Un sistema de salud reportó 2.5 millones de encuentros documentados por IA en 14 meses
Brecha de Validación
66%
de los médicos ahora usan herramientas de IA en el trabajo—un aumento del 78% desde 2023 (AMA, 2024)
La adopción está superando la validación. Las organizaciones están desplegando escribas de IA a escala sin la infraestructura de seguridad para detectar errores antes de que lleguen a los expedientes de pacientes.
¿Qué Es la Arquitectura PRISM?
Una arquitectura fundamentalmente diferente construida sobre un principio: separar lo que nunca debe mezclarse.
PRISM no es un mejor prompt. Es una mejor arquitectura. La investigación sobre sistemas de IA de múltiples etapas muestra que "las capas superiores manejando el establecimiento de objetivos y la descomposición de tareas, mientras las capas inferiores se enfocan en la ejecución... reduce la propagación de errores." PRISM aplica este principio a la documentación clínica.
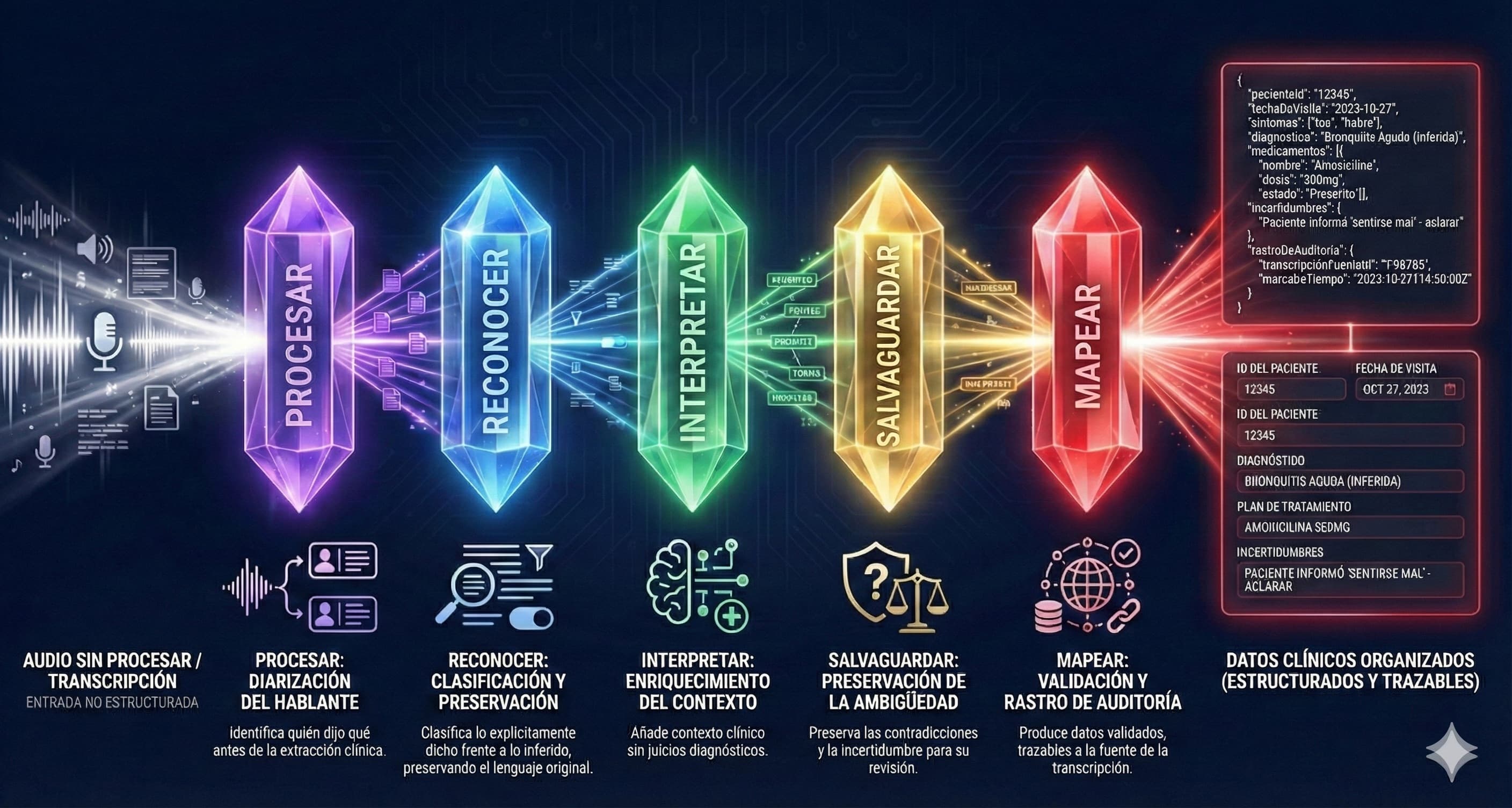
Cinco etapas. Cinco responsabilidades. Cero interferencia. Cada etapa recibe entrada solo de la etapa anterior, previniendo la interferencia catastrófica que aqueja a los sistemas de una sola pasada.
¿Cómo Funciona el Pipeline de 5 Etapas de PRISM?
Cada etapa tiene exactamente un trabajo—y restricciones arquitectónicas explícitas contra excederse. Esto no es ingeniería de prompts. Es diseño de sistemas.
Solo organización estructural
Atribución de hablantes. Manejo de interrupciones. Segmentación semántica. Determina quién dijo qué y dónde comienzan y terminan los temas. Sin interpretación clínica—solo estructura.
Extracción de datos con procedencia
Identifica elementos de datos clínicos con clasificación explícita vs. inferida. Etiqueta cada extracción como 'declarado por el paciente' o 'inferido del contexto.'
Solo enriquecimiento de contexto
Reconocimiento de patrones específico de medicina de emergencia. Identifica señales de agudeza, cadenas de mecanismos, relaciones temporales. Contexto sin juicio clínico.
Validación y auditoría
Asigna niveles de confianza. Preserva contradicciones en lugar de resolverlas. Rastrea cada salida a la fuente de la transcripción. Marca la incertidumbre para revisión del médico.
Solo generación de salida
Transforma datos validados e interpretados en documentación clínica estructurada. La etapa de ensamblaje final que solo produce lo que las etapas anteriores han verificado.
Cuando sus médicos revisan una extracción de PRISM, ven exactamente lo que el paciente dijo—no lo que una IA cree que quisieron decir. Cada elemento de datos se rastrea a su fuente. Cada incertidumbre se preserva.
¿Cómo Se Valida PRISM para la Seguridad Clínica?
No esperamos que PRISM funcionara. Lo probamos usando metodologías derivadas tanto de ingeniería de software como de investigación de seguridad clínica.
El marco RWE-LLM—que involucró a más de 6,200 clínicos con licencia en EE.UU. en más de 307,000 interacciones clínicas—estableció que la validación efectiva de IA requiere "clasificaciones de severidad estructuradas para problemas identificados en lugar de evaluaciones binarias de aprobado/reprobado." Adoptamos este principio.
Pruebas de Escenarios Adversarios
Siguiendo la metodología del benchmark CARES—que prueba "contenido dañino, vulnerabilidad a jailbreak y rechazos de falsos positivos"—diseñamos escenarios de prueba para cada modo de falla documentado.
| Escenario | Desafío | Resultado |
|---|---|---|
| Pediátrico | Padre habla por el niño | 94% |
| Psiquiátrico | Habla desorganizada | 100% |
| Trauma | Múltiples hablantes | 87% |
| Intérprete | Traducción de tres vías | 89% |
| Geriátrico | Historiador no confiable | 92% |
| Contradictorio | Paciente cambia la historia | 100% |
| Error Plantado | Metodología Mount Sinai | 100% |
Validación Multi-Modelo
La investigación indica que "los despliegues de un solo modelo se consideran insuficientes" para la seguridad clínica. PRISM fue validado en tres modelos de IA con capacidades dramáticamente diferentes.
Confiabilidad Reforzada por Arquitectura
Hemos superpuesto aprendizaje automático y herramientas de código abierto y conjuntos de datos del MIT sobre los últimos modelos LLM para validar una arquitectura que refuerza la corrección independientemente de la IA subyacente. Cuando llegue la próxima generación de modelo, el motor PRISM está listo.
¿Por Qué Era Imposible PRISM Antes de 2020?
Hace cinco años, construir PRISM habría requerido:
La revolución de los modelos de lenguaje grandes no solo hizo esto más barato. Hizo alcanzables capacidades previamente imposibles—pero solo con la disciplina de ingeniería adecuada. La mayoría de los proveedores tomaron el atajo. Nosotros no.
¿Por Qué Elegir PRISM Sobre los Escribas de IA de Primera Generación?
Puede desplegar escribas de IA que alucinan bajo presión, eliminan la incertidumbre de las declaraciones de los pacientes y lo dejan responsable por errores que no puede rastrear. O puede usar tecnología de documentación que fue diseñada para la medicina desde cero.
PRISM no es solo diferente. Es lo que diferente siempre debió significar.
Citas de Investigación
Mount Sinai (2025). Análisis de aseguramiento multi-modelo que muestra que los modelos de lenguaje grandes son altamente vulnerables a ataques de alucinación adversarios. Communications Medicine.
Shing et al. (2025). Un marco para evaluar la seguridad clínica y las tasas de alucinación de LLMs para la síntesis de texto médico. npj Digital Medicine.
Hanauer et al. (2012). Cubriendo sus Apuestas: El Uso de Términos de Incertidumbre en Documentos Clínicos. AMIA Annual Symposium Proceedings.
PMC (2025). Más allá de los oídos humanos: navegando los riesgos inexplorados de los escribas de IA en la práctica clínica.
Texas Medical Liability Trust. Usando escribas médicos de IA: Consideraciones de gestión de riesgos.
JAMA Network Open (2024). Perspectivas de los Médicos sobre Escribas Ambientales de IA.